

One of the first questions I get from new AI builders is always the same.
“How much is this going to cost me?”
So let me show you something from my own account.
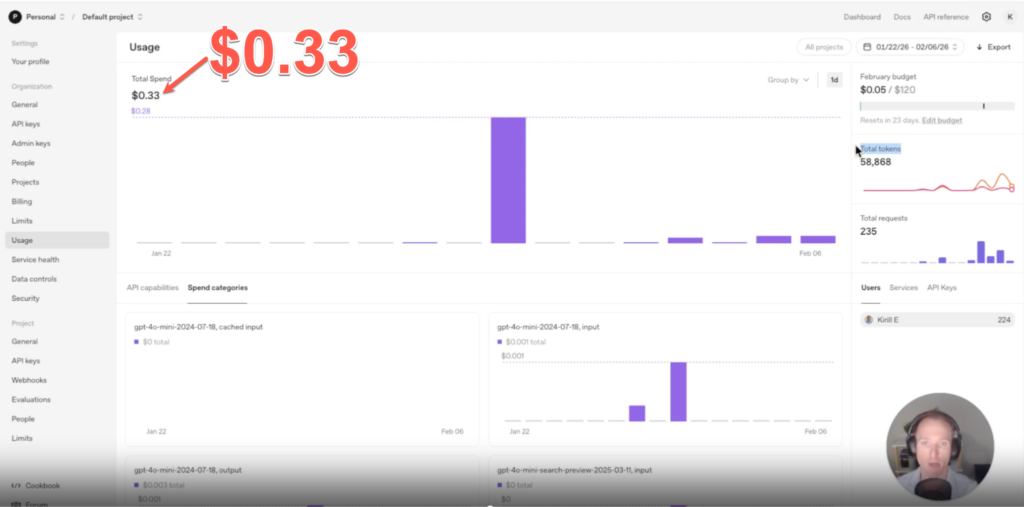
Two weeks of building and testing LLMs. Running queries, experimenting with models, and recording tutorials.
Total spend: 33 cents.
Most days were one or two cents. One day hit 28 cents. That was an outlier (I was testing the OpenAI search-enabled model).
For someone learning, the cost of running an LLM is basically nothing.
Here’s how it works.
LLMs charge by the token (think token=word for simplicity).
Every request has two components:
…input tokens (everything going into the model — your system prompt, conversation history, context, the user’s message)
…output tokens (everything the model generates back).
Typically, output is priced higher than input.
Important: with reasoning models, you’re also paying for hidden thinking tokens you never see.
Simple enough. But here’s where it gets interesting.
Once you start passing large amounts of context — say, 80,000 tokens of background information — costs can jump fast.
OR, if you’re building an app for 1000s of users, then even those 33 cents multiply!
That’s why you should know about Caching.
If the start of your prompt is identical between calls, the model doesn’t reprocess those tokens. It pulls from cache.
For OpenAI, cached input tokens cost 10 cents per million. Regular input is 40 cents.
Four times cheaper. Just for structuring your prompt correctly.
Rule of thumb: put repeating content first — system prompt, context, history.
Put changing content last: the user’s question / dates & times / etc.
If you change anything (even one token) at the start, the cache misfires. You pay full price.
Small decision. Big difference at scale.
Structure before you shrink,
Kirill
P.S. Caching rules vary by provider. OpenAI, Anthropic, and Gemini all handle it differently. Worth checking before you build.