
I’m going to mix it up a bit and give you something more technical this time.
My 3 progressive steps to learning RAG:
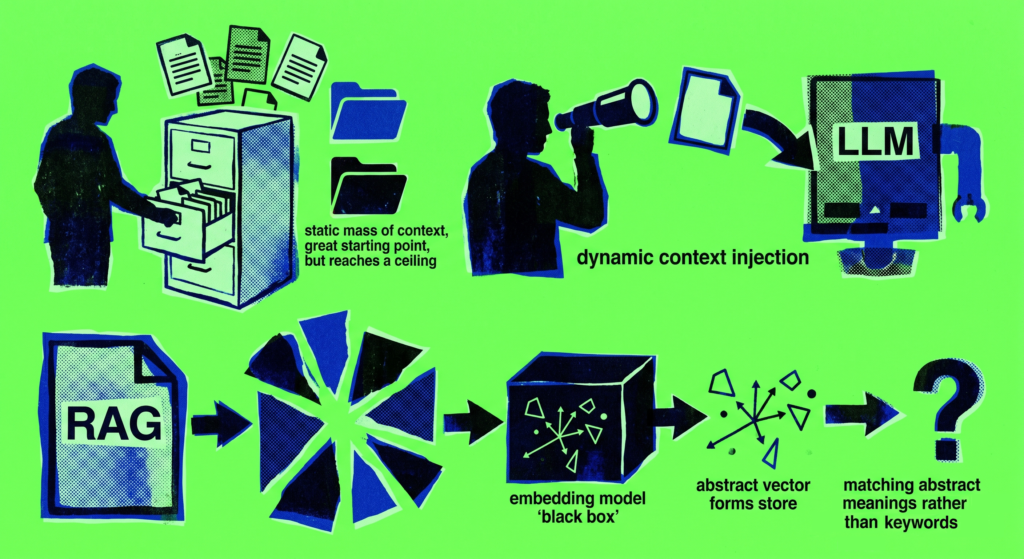
Most people building AI apps treat LLM context like a filing cabinet.
You open it, dump everything in, and hope the AI finds what it needs.
That works. Until it doesn’t.
The file gets too big. The AI gets confused. Responses get worse, not better.
Here’s how I teach RAG to our cohort members.
Step 1: Static context.
You start by crafting a strong system prompt. You tell the AI who it is, what it does.
Plus, you include some additional information it might need — an FAQ, a policy document, a product description.
Simple. Effective. A great starting point.
But as that document grows, you hit a ceiling.
Step 2: Dynamic context injection.
This is where it gets interesting.
Instead of dumping the whole document into context every time, you look at what the user is actually asking — and pull only the relevant piece.
Say someone asks about vacation days. Your code detects the keyword “vacation,” and automatically pulls just the vacation section of your HR policy and puts it into the context.
To be clear: your code is doing this part (not the AI).
The LLM gets exactly what it needs. Nothing more.
That already feels like a superpower.
Step 3: RAG.
RAG — Retrieval Augmented Generation — takes dynamic injection to another level entirely.
Instead of matching keywords, you match meaning.
Your document gets split into chunks. Each chunk gets passed through an embedding model, which converts it into a vector — a mathematical representation of its meaning. Those vectors get stored.
When a user asks a question, the system doesn’t look for matching words. It looks for matching meaning.
So even if the user says “annual leave” and your document says “vacation entitlement” — RAG finds the right chunk anyway.
Because it understood the intent, not just the words.
Keyword matching finds exact words.
RAG finds meaning.
Once our cohort members see this progression — static, dynamic, RAG — something clicks. They stop thinking about AI as a black box and start thinking about context as a craft.
To be fair, this was probably a 2.5min read.
But hopefully, it felt worth it.
Build better with AI,
Kirill
P.S. The embedding model that creates these vectors is completely separate from the LLM that answers questions.