

LSTM Practical Intuition
(For the PPT of this lecture Click Here)
Now we are going to dive inside some practical applications of Long Short-Term Memory networks (LSTMs). How do LSTMs work under the hood? How do they think? And how do they come up with the final output?
That’s going to be quite an interesting and at the same time a bit of magical experience.
In our journey, we will use examples from the Andrej Karpathy’s blog, which demonstrates the results of his amazing research on the effectiveness of recurrent neural networks. You should definitely check it out to feel the magic of deep learning and in particular, LSTMs. So, let’s get started!
Neuron Activation
Here is our LSTM architecture. To start off, we are going to be looking at the tangent function tanh and how it fires up. As you remember, its value ranges from -1 to 1. In our further images, “-1” is going to be red and “+1” is going to be blue.
Below is the first example of LSTM “thinking”. The image includes a snippet from “War and Peace” by Leo Tolstoy. The text was given to RNN, and it learned to read it and predict what text is coming next.
As you can see, this neuron is sensitive to position in line. When you get towards the end of the line, it is activating. How does it know that it is the end of the line? You have about 80 symbols per line in this novel. So, it’s counting how many symbols have passed and that’s the way it’s trying to predict when the new line character is coming up.

The next cell recognizes direct speech. It’s keeping track of the quotation marks and is activating inside the quotes.
This is very similar to our example where the network was keeping track of the subject to understand if it is male or female, singular or plural, and to suggest the correct verb forms for the translation. Here we observe the same logic. It’s important to know if you are inside or outside the quotes because that affects the rest of the text.

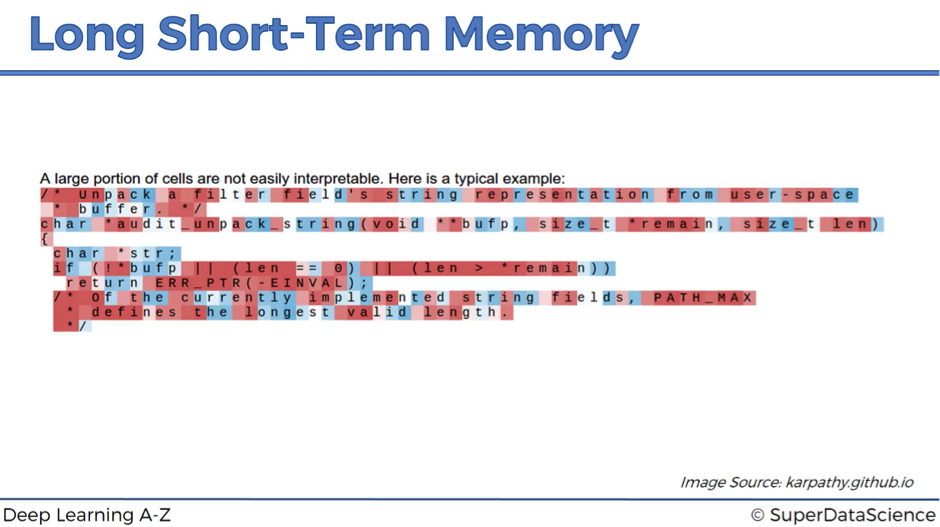
On the next image, we have a snippet from the code of the Linux operating system. This example refers to the cell that activates inside if-statements. It’s completely dormant everywhere else, but as soon as you have an if-statement, it activates. Then, it’s only active for the condition of the if-statement and it stops being active at the actual body of the if-statement. That’s can be important because you’re anticipating the body of the if-statement.

The next cell is sensitive to how deep you are inside of the nested expression. As you go deeper, and the expression gets more and more nested, this cell keeps track of that.

It’s very important to remember that none of these is actually hardcoded into the neural network. All of these is learned by the network itself through thousands and thousands of iterations.
The network kind of thinks: okay, I have this many hidden states, an out of them I need to identify, what’s important in a text to keep track off. Then, it identifies that in this particular text understanding how deep you’re inside a nested statement is important. Therefore, it assigns one of its hidden states, or memory cells, to keep track of that.
So, the network is really evolving on itself and deciding how to allocate its resources to best complete the task. That’s really fascinating!
The next image demonstrates an example of the cell that you can’t really understand, what it’s doing. According to Andrej Karpathy, about 95% of the cells are like this. They are doing something, but that’s just not obvious to humans, while it makes sense for machines.
Output
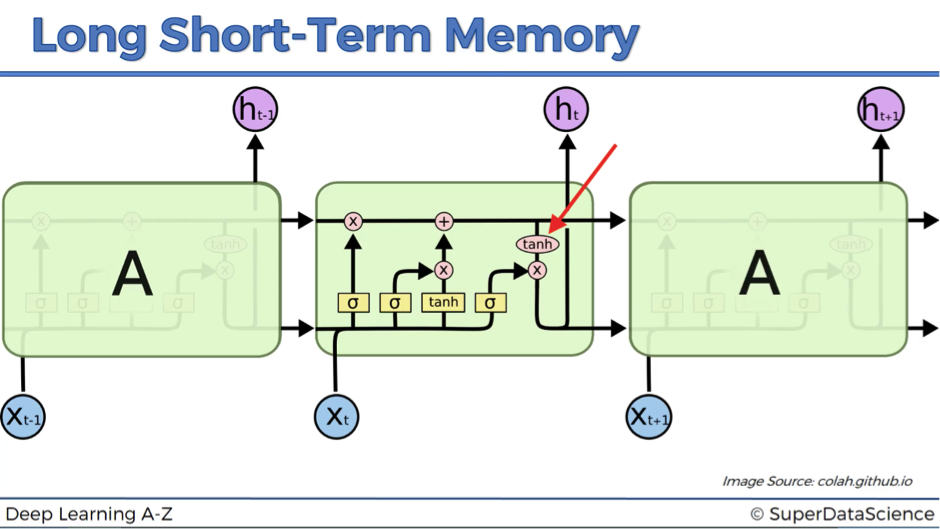
Now let’s move to the actual output ht. This is the resulting value after it passed the tangent function and the output valve.
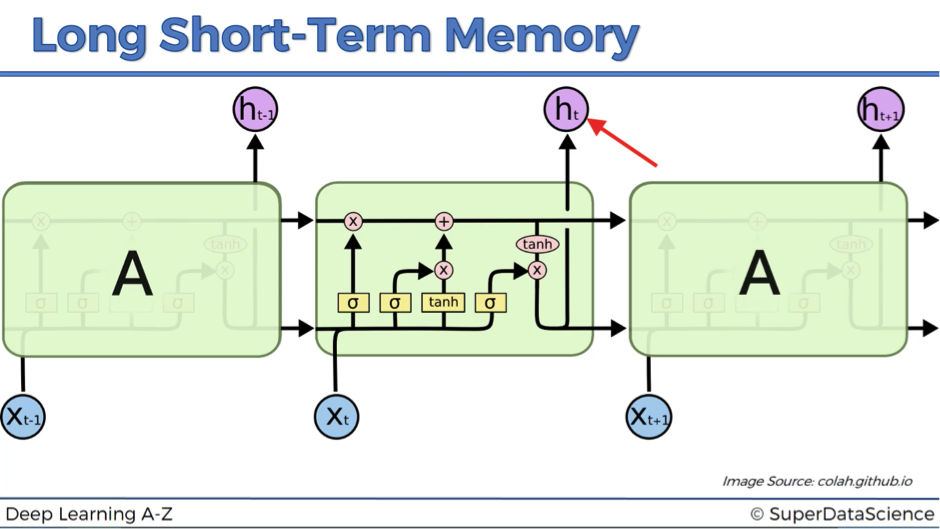
So, what do we actually see in the next image?
This is a neural network that is reading a page from Wikipedia. This result is a bit more detailed. The first line shows us if the neuron is active (green color) or not (blue color), while the next five lines say us, what the neural network is predicting, particularly, what letter is going to come next. If it’s confident about its prediction, the color of the corresponding cell is red and if it’s not confident – it is light red.
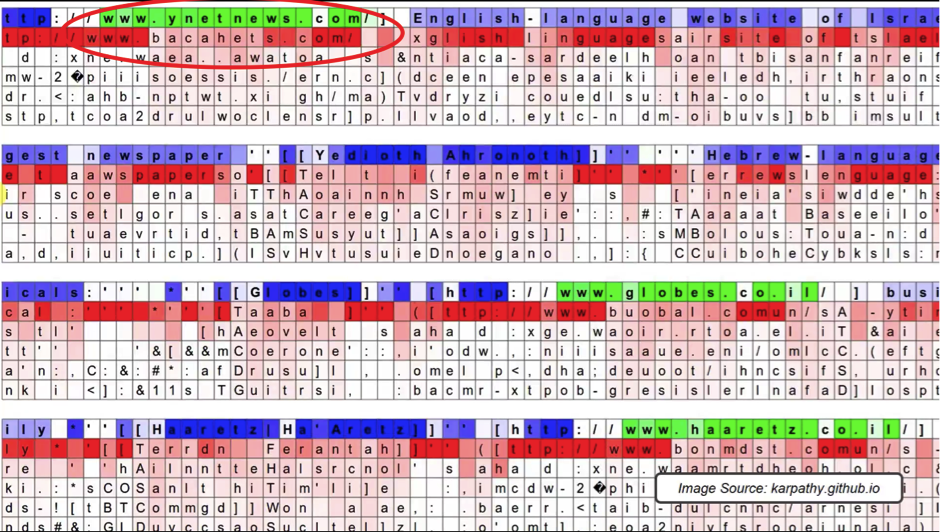
What do you think this specific hidden state in the neural network is looking out for?
Yes, it’s activating inside URLs!
The first row demonstrates the neuron’s activation inside the URL www.ynetnews.com. Then, below each of the letter you can see, what is the network’s prediction for the next letter.
For example, after the first “w” it’s pretty confident that the next letter will be “w” as well. Conversely, its prediction about the letter or symbol after “.” is very unsure because it could actually be any website.

As you see from the image, the network continues generating predictions even when the actual neuron is dormant. See, for example, how it was able to predict the word “language” just from the first two letters.
The neuron activates again in the third row, when another URL appears (see the image below). That’s quite an interesting case.
You can observe that the network was pretty sure that the next letter after “co” should be “m” to get “.com”, but it was another dot instead.
Then, the network predicted “u” because the domain “co.uk” (for the United Kingdom) is quite popular. And again, this was the wrong prediction because the actual domain was “co.il” (for Israel), which was not at all considered by the neural network even as 2nd, 3rd, 4th or 5th best guess.

This is how to look at this pictures that Andrej has created. There is a couple more of such examples in his blog.
Hopefully, you are now much more comfortable about what’s going on inside the neural network, when it’s thinking and processing information.
Additional Reading
In terms of references and additional reading, we’ve got Andrej Karpaty’s blog and a research paper prepared by Andrej Karpathy in cooperation with his colleagues:
- The Unreasonable Effectiveness of Recurrent Neural Networks by Andrej Karpathy (2015)
- Visualizing and Understanding Recurrent Networks by Andrey Karpathy et al. (2015)
This is actually a very exciting reading. You can see how the researchers “open up the brain” of the neural networks and monitor what’s happening in one specific neuron.
You actually feel from the language that this is if they are exploring some alien and how it thinks.
But wait! Humans created these LSTMs! However, they’ve become so advanced and complex, that we need now to study them as if they are separate beings.
Isn’t this exciting? Make sure to check the articles if you also want to feel this magic.