

What are Convolutional Neural Networks?
(For the PPT of this lecture Click Here)



In this tutorial, we’re going to answer the following questions in the most basic sense before expanding on each of them in the coming tutorials in this section:
- How do our brains work?
- How do convolutional neural networks work?
- How do they scan images?
- How do neural networks read facial expressions?
- What are the steps that constitute the convolutional neural network’s process?
Let’s begin.
First Question: How does the human brain work?
More precisely, how do we recognize the objects and the people around us or in images? Understanding this is a large part of understanding convolutional neural networks. In a nutshell, our brains depend on detecting features and they categorize the objects we see accordingly.
You have probably been through hundreds of situations in your life where you looked at something instantaneously, made it out to be something, and then after looking at it more thoroughly, you realize that it is actually something completely different.
What happens there is that your brain detects the object for the first time, but because the look was brief, your brain does not get to process enough of the object’s features so as to categorize it correctly.
Let’s start with a brief game of optical illusions. Look at the following images:
Do you see an old lady looking down or a young lady staring away?
Do you see a rabbit or a duck?
That’s enough with the games. The point to be made here is that your brain classifies objects in an image based on the features that it detects first.
The previous images were designed so that what you see in them depends on the line and the angle that your brain decides to begin its “feature detection” expedition from.
As we proceed in our section on convolutional neural networks, you will realize the staggering degree of similarity between how these networks operate and how your brain does. They, too, categorize objects or images based on the set of features that are passed through them and that they manage to detect.
Now let’s look at an example of a test set that is fed to a convolutional neural network and the results that the network gave.
It’s worth noting that the four categories that show up on this guess list are far from being the only categories that the network gets to choose from.
It usually has to sift through hundreds, or more likely thousands, of categories until it shortlists the ones you see in the image above, which it then ranks according to their probability of being the right category for the presented image.
You can see that the network was not as certain about the last image as it was about the first two. We can infer from this that one major thing about convolutional neural networks that you should always take into account is that the poor bastards often get confused at least in their earlier stages of training.
Just like your brain oftentimes mistakenly categorizes objects at first sight, convolutional neural networks are prone to the same indecision when presented with an object or an image from an angle that can easily place it under more than one category.
As a matter of fact, with that very image in the screenshot above, many humans are uncertain of what the object actually is. As we can see, the correct answer was “hand glass,” not a pair of scissors as the network categorized it.
Why Convolutional Neural Networks are so important
To understand this, you can ask yourself a couple of simple questions:
- How do self-driving cars recognize other cars as well as pedestrians and street objects?
- How did Facebook go from making you tag people in images yourself, to being able to identify your friends and automatically tag them as it does now?
And the answer to both questions would be: through the magic of convolutional neural networks.
So, how do Convolutional Neural Networks actually operate?
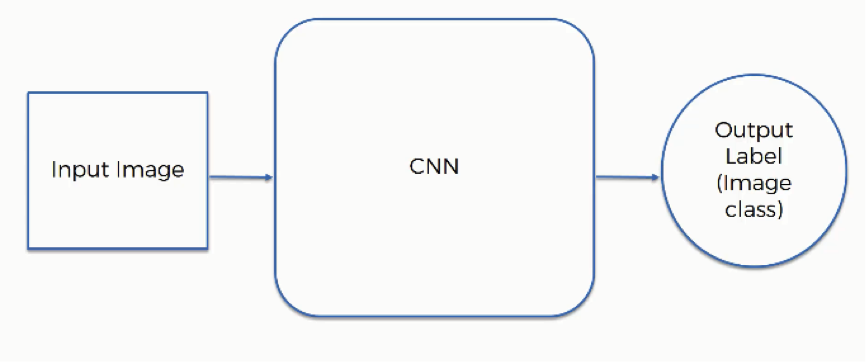
The first thing you need to know here is the elements that are included in the operation:
- Input image
- Convolutional Neural Network
- Output label (image class)
These elements interact in the following manner:
We already saw how convolutional neural networks can categorize images according to the objects included in them. That is not their only use, however.
For example, convolutional neural networks can be used in detected human emotions in an image. You provide them with someone’s photo, and they produce a classification to the effect of what that person seems to be feeling.
Of course, this requires a somewhat more advanced level of training since being able to infer someone’s emotions from their facial expressions is often quite a puzzling task to humans themselves.
Naturally, only a small portion of people can do so with a fairly high degree of success.
HOW CONVOLUTIONAL NEURAL NETWORKS SCAN IMAGES
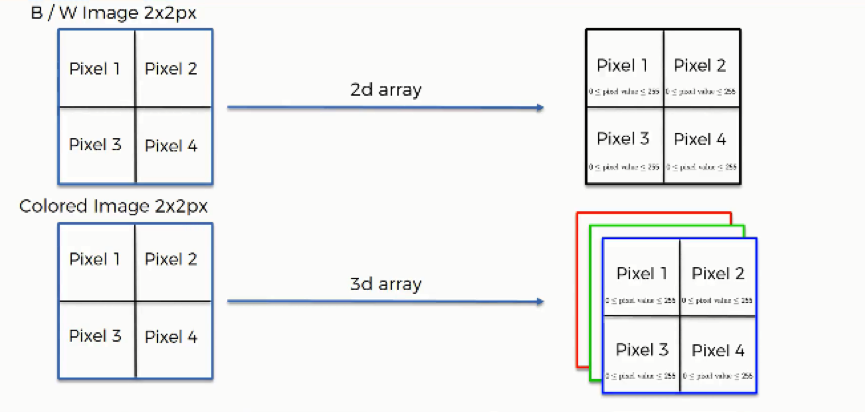
Before getting into the details of this operation, you should first keep in mind that the way black & white images are scanned differs in one major way from how colored images are. We’re going to examine each of them separately, but first, let’s look at the similarities.
Both types of images are similar in the following respects:
- Each pixel contains 8 bits (1 byte) of information.
- Colors are represented on a scale from 0 to 255. The reason for this is that bits are binary units, and since we have 8 of these per byte, a byte can have any of 256 (2^8) possible values. Since we count 0 as the first possible value, we can go up to 255.
- In this model, 0 is pitch black and 255 is pure white, and in between are the various (definitely more than 50!) shades of gray.
- The network does not actually learn colors. Since computers understand nothing but 1’s and 0’s, the colors’ numerical values are represented to the network in binary terms.
Now let’s delve into the major difference that we mentioned above.
Black & white images are two-dimensional, whereas colored images are three-dimensional. The difference this makes is in the value assigned to each pixel when presented to the neural network. In the case of two-dimensional black & white images, each pixel is assigned one number between 0 and 255 to represent its shade.
On the other hand, each pixel inside a colored image is represented on three levels. Since any color is a combination of red, green, and blue at different levels of concentration, a single pixel in a colored image is assigned a separate value for each of these layers.
That means that the red layer is represented with a number between 0 and 255, and so are the blue and the green layers. They are then presented in an RGB format. For example, a “hot pink” pixel would be presented to the neural network as (255, 105, 180).
Detecting facial expressions
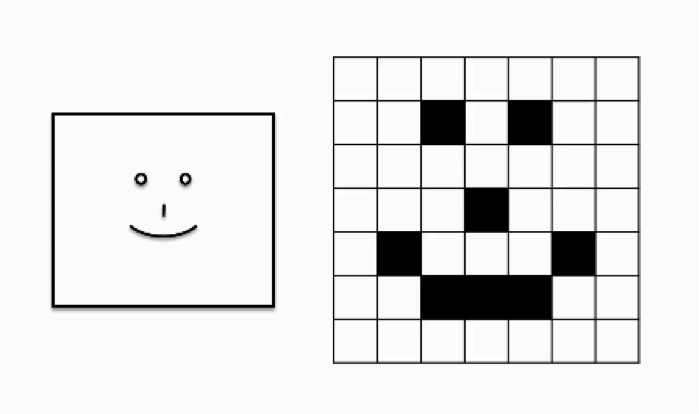
Let’s look at a case in which a convolutional neural network is asked to read a human smile. For the purpose of simplification, the following figure shows an extremely basic depiction of a human (loosely speaking, of course) smile.
Matters obviously get more complex when we’re trying to feed the network pictures of actual human beings.
As you can see, the grid table on the far right shows all of the pixels valued at 0’s while only the parts where the smiley face appears are valued at 1. This differs from the 8-bit model we just discussed, again, for the sake of breaking down the concept.
In the table above, white cells are represented as 0’s, and black cells are represented as 1’s, which means that there are no other possible shades that can appear in this image.
What we do when training a convolutional neural network to detect smiles is to teach it the patterns of 0’s and 1’s that are normally associated with the shape of a smile.
If you look at the arc of 1’s that ends in the second row from the bottom you would be able to recognize the smile.
The steps that go into this process are broken down as follows:
You will probably find these terms to be too much to digest at the moment, which is quite normal at this point. As we go through the next tutorials, you will get to understand what each of them actually means.
Continue with Step 1: Convolutional Neural Networks by Clicking Here
Additional Reading
In the meantime, if you want to geek out on some extra material, you should check out this paper titled “Gradient-Based Learning Applied to Document Recognition” by Yann LeCun and others.
LeCun is considered to be one of the founding fathers of the field of convolutional neural networks, and he was the first person to head the Facebook AI Research organization in New York before stepping down earlier this year.
So, if there is someone who can give you the gist of the subject, it is definitely this guy.
Now it’s time for you to do some reading on the topic so you can get more familiar with the broad concept of convolutional neural networks, and in the next tutorial we will begin to break it down into its four basic steps.
