

The Activation Function
(For the PPT of this lecture Click Here)


In this tutorial we are going to examine an important mechanism within the Neural Network: The activation function.
The activation function is something of a mysterious ingredient added to the input ingredients already bubbling in the neuron’s pot.
In the last part of the course we examined the neuron, how it works, and why it is important.
The last section and this one are intrinsically linked because the activation function is the process applied to the weighted input value once it enters the neuron.
Values
If weighted input values are shampoo, floor polish, and gin, the neuron would be the deep black pot. The activation function is the open flame beneath that congeals the concoction into something new; the output value.
Just as you can adjust the size of the flame and time you wish to spend stirring, there are many options you can process your input values with.
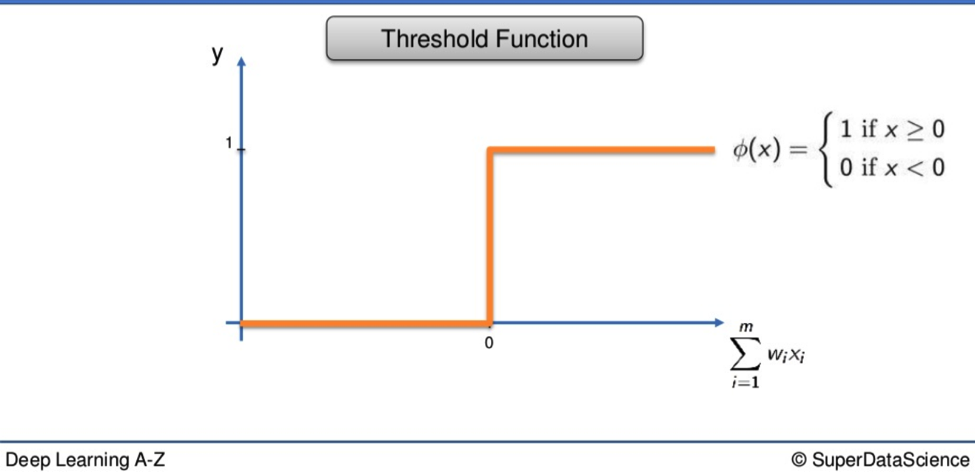
The Threshold Function
The first is the simplest. The x-axis represents the weighted sum of inputs. On the y-axis are the values from 0 to 1.
If the weighted sum is valued as less than 0, the TF will pass on the value 0. If the value is equal to or more than 0, the TF passes on 1.
It is a yes or no, black or white, binary function.
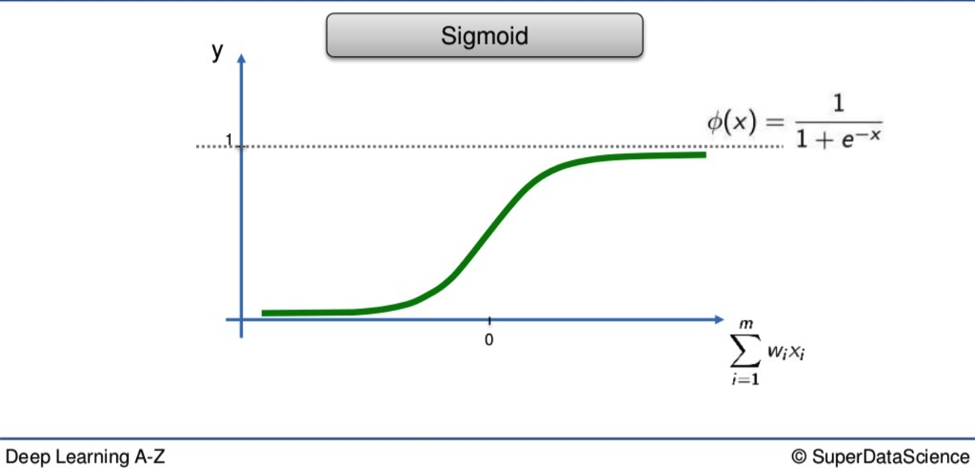
The Sigmoid Function
Here is the second method. With the Sigmoid, anything valued below 0 drops off and everything above 0 is valued as 1.
Shaplier than its rigid cousin, the Sigmoid’s curvature means it is far better suited to probabilities when applied at the output layer of your NN.
If the Threshold tells you the difference between 0 and 1 dollar, the Sigmoid gives you that as well as every cent in between.
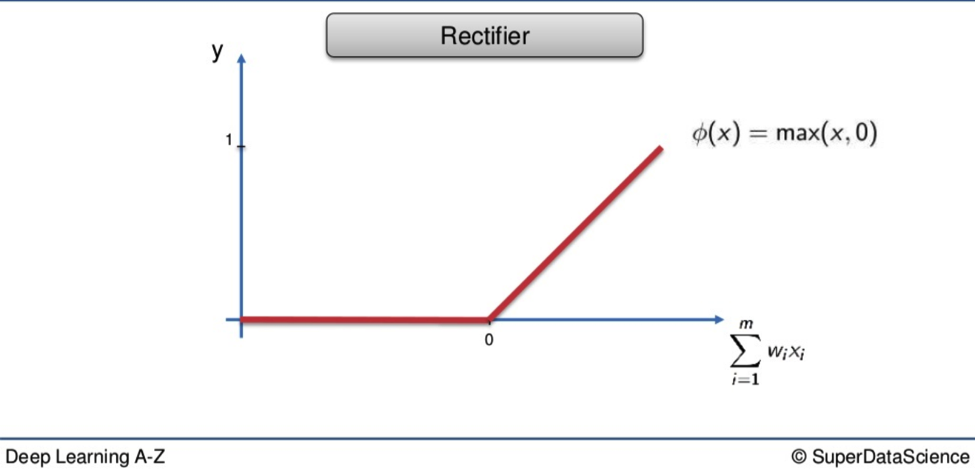
The Rectifier Function
Up next we have one of the most popular functions applied in global Neural Networking today, and with the most medieval name.
You can see why so many people love it.
Look at how the red line presses itself against the x-axis before exploding in a fiery arrow at 45 degrees to a palace above the clouds. Who wouldn’t want a piece of that sweet action?
Its spectacle is matched only by its generosity. Every value is welcome at the party. If a weighted value is below 0 it doesn’t just get abandoned, left to float through time and space between stars and pie signs. It is recruited, indoctrinated. It becomes a 0.
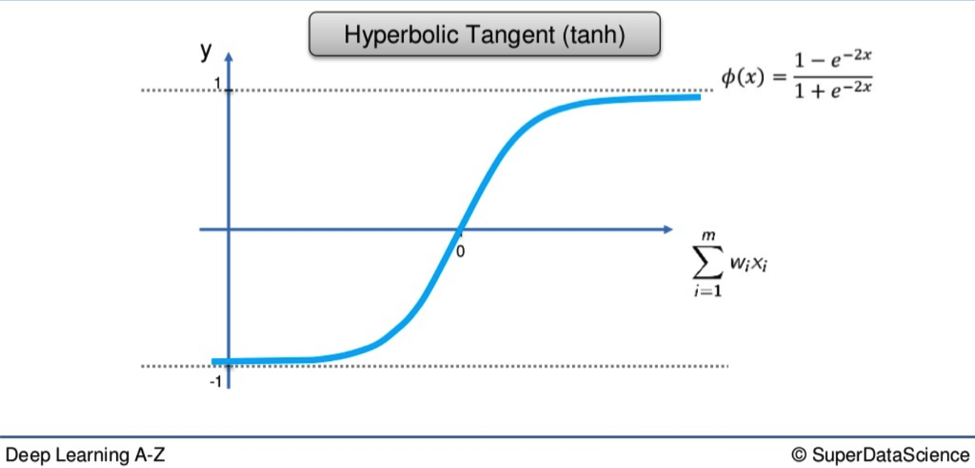
Hyperbolic Tangent Function
Following an act like that was never going to be easy, but the Hyperbolic Tangent Function (tanh), gives it a bloody good go.
Tanh is the Dante of the activation functions.
It is willing to delve deep below the x-axis and its 0 value to the icy pits of the lowest circle, where the value -1 slumbers.
From there it soars on a route similar to that of the Sigmoid, though over a greater span, all the way to blessed 1.
Conclusion
Obviously, this has not been an intensely focused piece on the nuts and bolts of activation functions.
The purpose of this deep learning portion has been to familiarize you with these functions as concepts and to show you the differences between one function and the next.
However, it would be remiss of me to exclude those wanting something more involved.
Additional Reading
I recommend the paper Deep sparse rectifier neural networks by Xavier Glorot et al. (2011). The link is here.
It is not essential you read through such dense material yet. I am more concerned with you applying these functions rather than understanding them absolutely. Once you feel comfortable with the practical applications, then the information in the link above will make more sense.
That’s all for now. I hope it was all easily digestible. In the next section, I will help you understand how Neural Networks work.